


Overconfidence in State of the Art LLMs
[Research Paper] Alice in Wonderland - Complete Reasoning Breakdown in SOTA LLMs


State of the Art LLMs have been competing to beat benchmarks in speed, pricing and quality, but even with the current metrics, does it actually give a full picture of what these LLMs are capable of? and how often does LLMs make a mistake?
These are question that might not be a big deal in a personal use setting, but when you start thinking of enterprise solution or integrating LLMs in your own work flow, these mistakes can cost you thousands if not millions.
Quality metrics like MMLU provide a good sign that an LLM is diverse and knowledgable enough, I might be butchering it, so here is Wikipedia’s definition
Measuring Massive Multitask Language Understanding (MMLU) is a benchmark for evaluating the capabilities of language models. It consists of about 16,000 multiple-choice questions spanning 57 academic subjects including mathematics, philosophy, law, and medicine. It is one of the most commonly used benchmarks for comparing the capabilities of large language models.
and it looks like the place to go for these benchmarks and metrics, are platforms like Chatbot Arena and Artificial Analysis.
but as Mr. Einstein once said, sometimes …
“Not everything that can be counted counts, and not everything that counts can be counted“
Alice in Wonderland research paper, is a case that is challenging SOTA LLMs to a a problem that is pretty easy for a human to solve with some relational logic.
Alice has two brothers and 3 sisters, how many sisters do the brothers have?
Surprisingly, many models failed to answer correctly, revealing significant gaps in their reasoning capabilities.



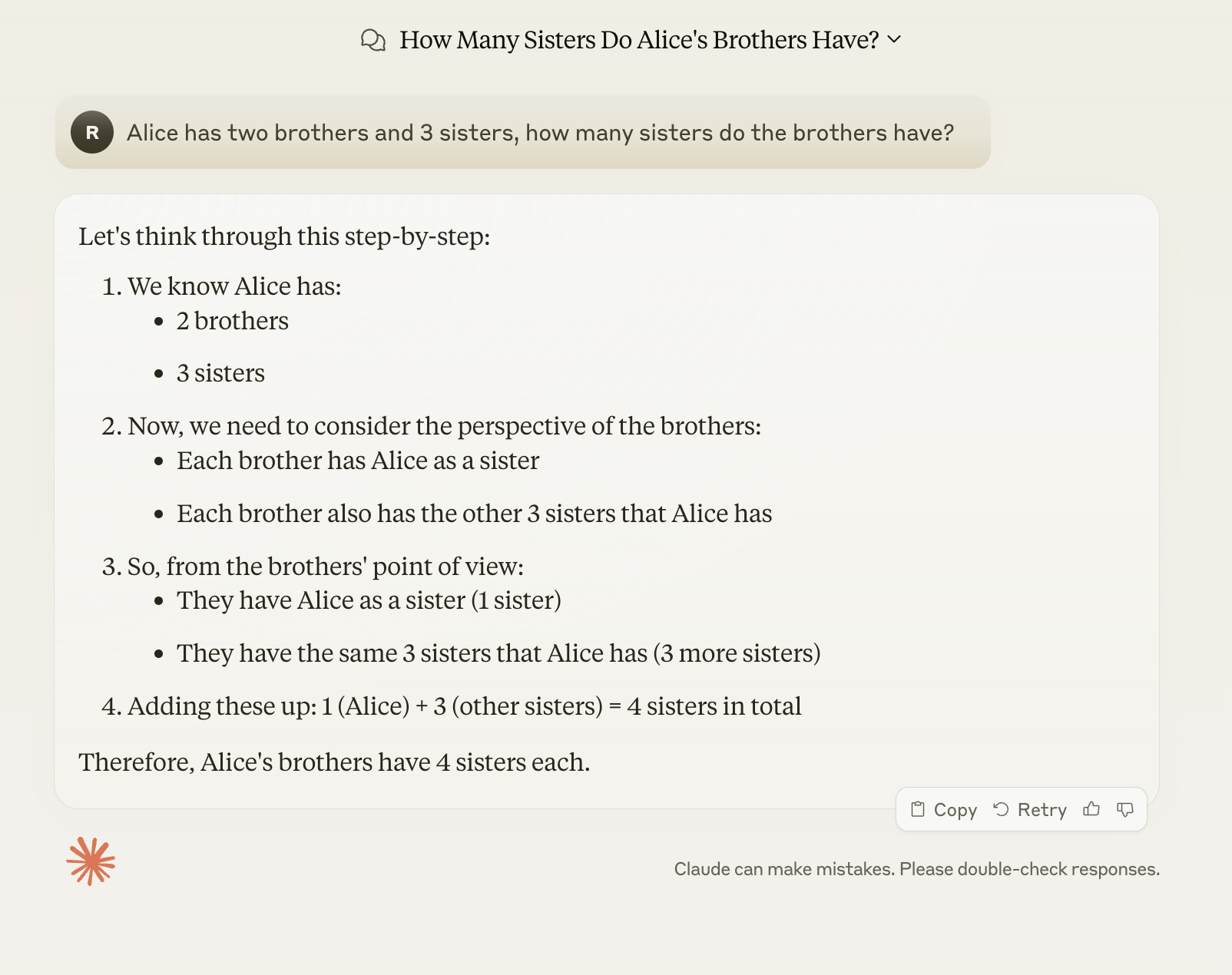
Wrong & Overconfident
Not only it is wrong, the research paper explains a major issue with LLMs when it comes to explaining the reasoning behind the wrong answer, which if left to a user without an analyst lens and heavy auditing, can be really convincing, by how elaborate it is. Big models like GPT-4 and Claude Opus, produced occasional correct answers, but it is not consistent.
While LLMs excel in tasks such as few-shot and zero-shot learning, their performance on simple reasoning tasks raises questions. High scores on standardized benchmarks do not always translate to effective problem-solving in straightforward scenarios. This discrepancy was evident when most tested models, including popular ones like GPT-3.5 and Claude 3 Opus, failed to consistently solve the "Alice in Wonderland" (AIW) problem.
What can we do about it?
Acknowledgment, yes! acknowledging that LLMs are not in anyway in a place where it can take critical reasoning decisions without supervision, and the human specialized eye is still king.
LLMs are getting better with scaling and being trained on high quality data, but till another advancement happen on the reasoning skill, I believe addressing these gaps involves leveraging human expertise to validate and guide AI outputs, especially in critical applications, which can mitigate the risk of costly mistakes.
I think the lesson from this research paper is; achieving high benchmark scores is a great indication of capability, but solving the challenge in ensuring consistent, logical, and reliable performance across a variety of tasks from LLMs is still work in progress.
Great synopsis. I think it would be interesting if somebody built a framework to identify these "hard problems" (questions with consistent wrong answers and high fluctuations on variations >> high uncertainty). One could then start building an "MMLU+ / hard benchmark dataset" that could serve as a) a new standard for evaluating reasoning, b) a starting point for better understand why these problems are so difficult for LLMs, and c) a starting point for fine-tuning efforts as a short term solution.